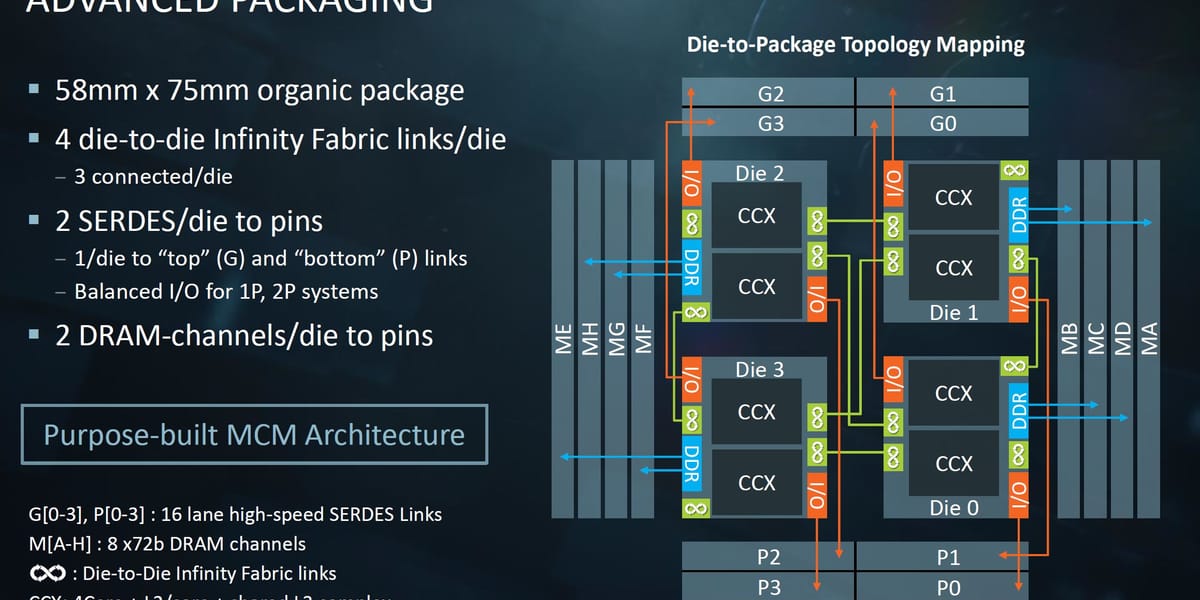
Con la Ley de Moore cada vez los diseños históricos monolíticos son cada vez más caros de fabricar. No es ningún secreto que tanto AMD como NVIDIA han estado explorando un enfoque MCM (Módulo Multi-Chip) para desviar de diseños de matrices monolíticas a un diseño "chiplet" mucho más manejable. Esencialmente, AMD lo ha logrado de diferentes maneras con su línea Zen de CPU (dos módulos de CPU de cuatro núcleos conectados mediante la interconexión Infinity Fabric de la empresa) y sus propias tarjetas gráficas R9 y Vega, que adoptan otro enfoque en la memoria de empaquetado y el el procesamiento de gráficos muere en la misma base de silicio: una intercalación.

Diferencias entre chips monolíticos contra chips MCM
Esquema de paso de los chips monolíticos al Módulo Multi-Chip
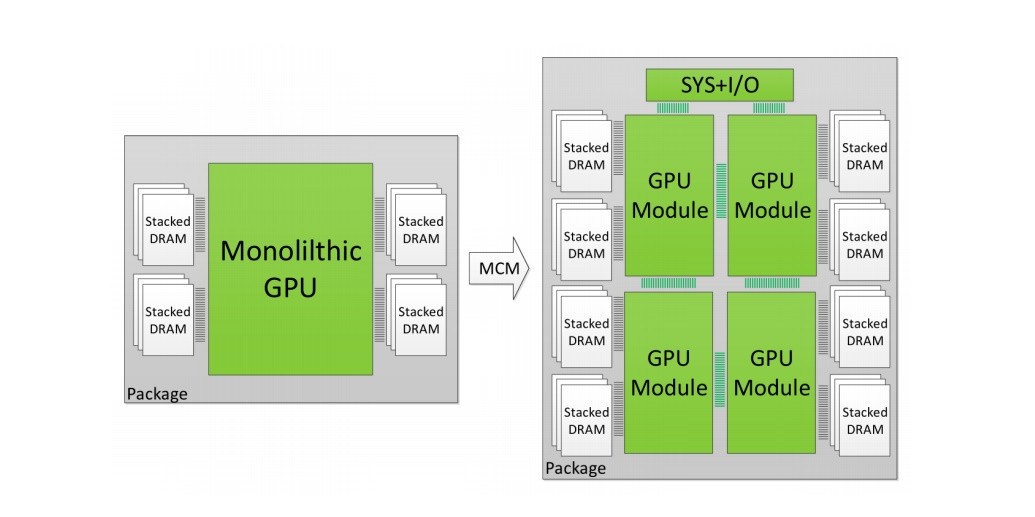
Este enfoque de "chiplet" es fácil de entender: se pueden producir chips más pequeños y más delgados con mayores rendimientos que los grandes y monolíticos, que son más propensos a los defectos de silicio. Este mayor rendimiento (y un mayor número de chips por oblea, al final) permite a AMD reducir los costos de fabricación y aumentar la eficiencia de producción mediante el uso de una sola máscara para un módulo de cuatro núcleos, por ejemplo. Después, es "simplemente" una cuestión de escalar la cantidad de módulos a la cantidad deseada y el paradigma de rendimiento, desde CPU Ryzen de ocho núcleos hasta CPU Threadripper II de 32 núcleos.
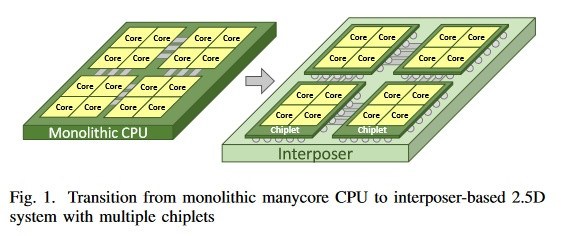
Comparación diseño monolítico contra el diseño chiplet
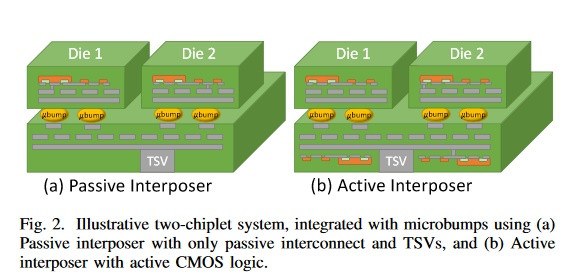
Varios chiplets unidos
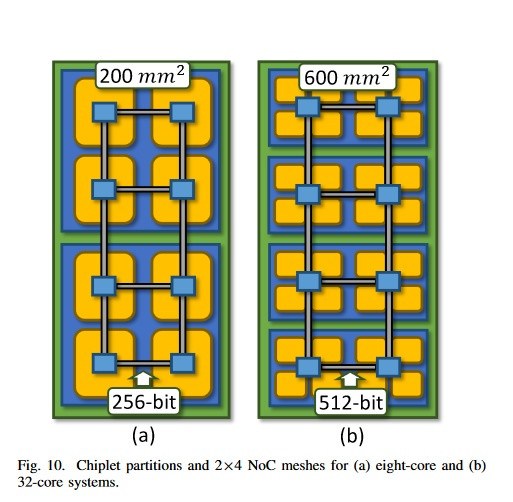
Sin embargo, a medida que aumenta el número de módulos en un chip dado, también lo hace la complejidad del procesamiento de la señal y el enrutamiento. Es relativamente fácil lograr dos módulos que se comunican entre sí, ¿pero seis u ocho módulos? No tanto, ya que un pequeño inconveniente en la transmisión de información puede bloquear el procesador completo (ya sea aquí hablando de diseños de CPU o GPU). El desafío se vuelve cada vez mayor cuando se unen diferentes tipos de chips, desde la memoria hasta las matrices de procesamiento y los controladores E/S, en una sola división de silicio. Aquí es donde aparecen los intercaladores, y donde AMD está avanzando hacia el logro de un diseño de interposición activa.
Los intercaladores pasivos, como el que se encuentra en las tarjetas gráficas AMD Vega, son simplemente un habilitador del silicio para la transmisión de datos: la información se envía exactamente como se diseñó con el diseño TSV (Through Silicon Vias). Sin embargo, este enfoque es insuficiente en el enfoque abierto y soñado para la integración de chips, donde los fabricantes pueden crear sus diseños, comprar otros chips de otras compañías y mezclar y combinar según los requisitos de sus productos finales.
Un intercalador pasivo no será suficiente aquí debido a los problemas de enrutamiento de datos tendrían que resolverse manualmente con cada implementación diferente, lo que es prohibitivo desde la perspectiva del coste, y un gran no para el enfoque.
La solución, como AMD lo pone en su documento "Diseño rentable de sistemas de alto rendimiento escalables mediante interpoladores pasivos y activos", se puede encontrar, al menos parcialmente, con un intercalador activo, un intercalador que presenta lógica de red (NoC, Network on Chip) que se puede adaptar a los diferentes cortes de silicio injertados en él. Y esto no es solo teórico: se han fabricado diseños de intercaladores activos que muestran "señalización mejorada y eficiencia sobre interposición pasiva".
Sin embargo, un gran problema para este enfoque de interposición activa es el coste, una vez más, el final de muchas tecnologías prometedoras. AMD, sin embargo, está trabajando activamente en la creación de redundancia suficiente en el diseño del intercalador activo que los rendimientos no son una gran preocupación: lograr un punto intermedio entre el costo de desarrollo y la relación de rendimiento. No hay nada peor que pagar un intercalador activo de área grande con todos sus circuitos de red y que tenga tales defectos que no se pueda usar.
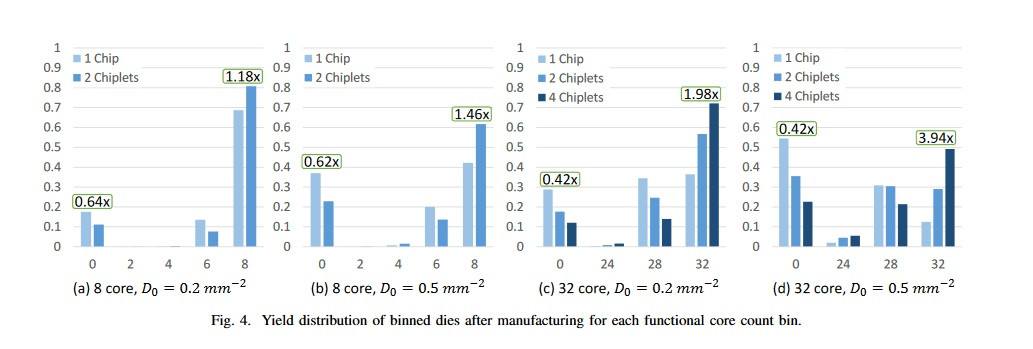
Por ahora, AMD dice que estos intercaladores activos deberían reservarse para diseños de alto rendimiento, lo que no es sorprendente dado el costo adicional de I+D sobre el intercalador pasivo o el diseño sin interposición. El sueño de mezclar, combinar y reutilizar diferentes IP a voluntad a través de un sustrato "simple", sin embargo, está muy vivo. Investigadores de AMD demostraron que para procesadores de 32 núcleos con posibilidades de escalamiento con complejidad estimada de troquel monolítico contra el enfoque chiplet podría lograrse con mucho mejor rendimiento y menor coste de fabricación en el diseño intercalado chiplet + pasivo/activo frente a un troquel monolítico de 16 nm.
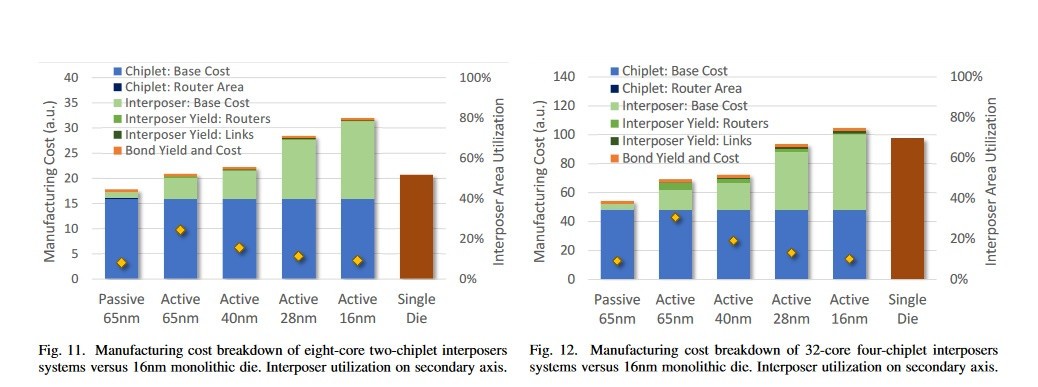
El proceso utilizado para fabricar el intercalador es muy importante en este caso: a fin de aumentar las relaciones de rendimiento, las soluciones activas o pasivas de 65 nm a 28 nm proporcionan costes de desarrollo y fabricación reducidos. Los intercaladores activos, aunque son más caros que sus contrapartes pasivas, agregan las capacidades de red antes mencionadas que permiten la posibilidad de un punto muerto cero, enrutando las señales según sea necesario entre los diferentes componentes del diseño.